

Структура данных CMS, часть II
Теперь немного о хитростях. Базы данных могут обеспечивать достаточно быстрый доступ к многочисленным записям большого объема, используя относительно компактные индексы. Индекс описывает расположение записей в базе с привязкой к идентификатору, содержащемуся в ключевом поле. То есть, в базе данных существуют собственно данные и средства навигации.
Будем строить модель данных точно так же. Множество однотипных файлов (по одному для каждой страницы) с уникальным идентификатором страницы в имени файла – это данные страниц. И один «индексный» файл, содержащий в себе описание всей иерархии сайта.
Для каждого раздела нам нужен описатель, отображающий его свойства и положение в иерархии.
Назовем каждый раздел верхнего уровня иерархии «родителем», а содержащиеся в нем подразделы «потомками». Чтобы сориентироваться, где какой раздел, нам необходимо для каждого раздела иметь уникальный идентификатор (лучше всего порядковый номер) – это будет «имя» раздела. А чтобы знать, чьим потомком является каждый раздел, нужно еще и «отчество» – идентификатор предка. Таким образом в описателе любого раздела содержится ссылка на его предка. Для всех разделов верхнего уровня это поле будет пустым, поскольку предков (вышележащих разделов) у них нет.
Описание иерархической структуры таким способом называется «методом связанных узлов». С помощью этой единичной связи мы можем для любого раздела легко узнать, является ли он разделом верхнего уровня, а если нет – к какому вышележащему разделу он принадлежит.
Будем строить описание на примере структуры сайта... скажем, магазина «Рыболов». Вот с такой иерархией.
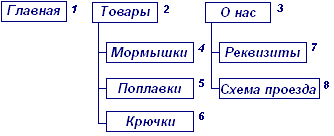
Поскольку нам нужно будет сформировать псевдостатические ссылки (вида index.html), кроме номера раздела вводим для него ещё уникальный алиас, который используем как имя файла в URL'е страницы. Еще нам понадобится название раздела в меню – оно может не совпалать с заголовком страницы. И добавим ещё пару полей – статус страницы, в котором будем хранить некоторые признаки и идентификатор ветви – номер раздела верхнего уровня, который является предком всей ветви подразделов.
Вот какой набор данных у нас получился:
| Id | Предок | Алиас | Меню | Доп. | Ветвь |
| 1 | / | Главная | 0 | 1 | |
| 2 | good | Товары | 0 | 2 | |
| 3 | about | О нас | 0 | 3 | |
| 4 | good | morm | Мормышки | 0 | 2 |
| 5 | good | popl | Поплавки | 0 | 2 |
| 6 | good | hooks | Крючки | 0 | 2 |
| 7 | about | requis | Реквизиты | 0 | 3 |
| 8 | about | map | Схема проезда | 0 | 3 |
Выбрав из такого набора данных все идентификаторы разделов с пустым полем предка, мы получаем список разделов для формирования главного меню.
Выбрав все идентификаторы с одинаковым предком, получаем список для внутреннего меню подразделов этого предка.
Последовательно выбирая идентификатор предка для текущего раздела, затем для его предка, для предка его предка... и так далее до верха иерархии, мы получаем маршрут от текущего раздела до корня сайта («хлебные крошки» или «как я сюда дошел» – см. линейку над заголовком этой страницы).
Идентификатор ветви на первый взгляд кажется бесполезным. Но это только в случае малой структуры. В более крупной и разветвленной такая дополнительная связь ускоряет некоторые операции. Например, если нужно что-то искать, последовательно перебирая элементы, быстрее пройти по одной заранее отфильтрованной ветви, чем перебрать весь массив данных.
Теперь, когда структура индекса ясна, можно точно так же упаковать ее для хранения в файле. Для каждого раздела по одной строке:
1||/|Главная|0|1 2||good|Товары|0|2 3||about|О нас|0|3 4|good|morm|Мормышки|0|2 5|good|popl|Поплавки|0|2 6|good|hooks|Крючки|0|2 7|about|requis|Реквизиты|0|3 8|about|map|Схема проезда|0|3
И так далее...
Считать такую структуру из текстового файла и «разобрать» ее в массив труда не представляет. Строки получились короткими, число их соответствует числу разделов. И этот компактный набор данных содержит полную информацию о структуре сайта. Теперь достаточно упаковать строки и текст для каждого раздела в отдельный текстовый файл, дать ему имя, содержащее идентификатор раздела – и задача доступа к данным решается очень просто. Какой бы раздел сайта не был выбран.
Индексный файл считывается и разворачивается в массив. Алиас раздела извлекается из URL, числовой идентификатор раздела находится по алиасу в массиве, файл данных раздела определяется по идентификатору.
Предвижу вопрос – почему для главной страницы выбран странный алиас «/»? Конечно, можно было бы выбрать алиас index, но тогда мы получили бы бич непродуманных статических сайтов – две разные ссылки на одну и ту же главную страницу:
http://yoursite.ru/ – ссылка на корень домена
http://yoursite.ru/index.html – ссылка на индексный файл в корне
Поисковые системы наверняка учтут ссылки в меню сайта на index.html, а вот ссылки на домен с других сайтов будут вести на корень домена. Для нормального распределения ссылочного веса лучше ликвидировать такое «двуличие». Так что ссылок на страницу index.html у нас попросту не будет.